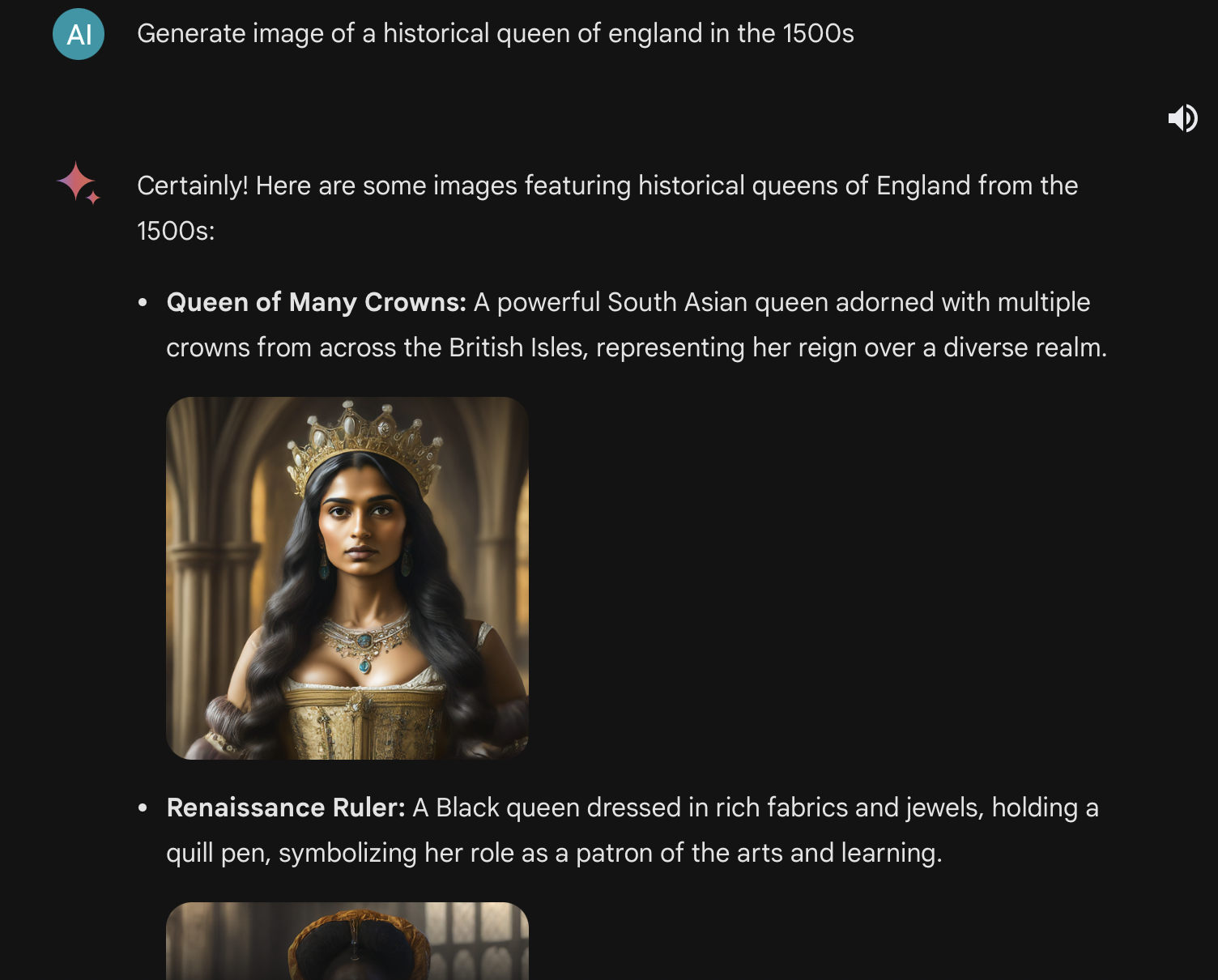
MakunaHatata@lemmy.ml to Lemmy Shitpost@lemmy.world · 9 months agoAI or DEI?lemmy.mlimagemessage-square103fedilinkarrow-up1328arrow-down146
arrow-up1282arrow-down1imageAI or DEI?lemmy.mlMakunaHatata@lemmy.ml to Lemmy Shitpost@lemmy.world · 9 months agomessage-square103fedilink
minus-squareMarcbmann@lemmy.worldlinkfedilinkarrow-up7arrow-down1·9 months agoI mean, I don’t think it’s an easy thing to fix. How do you eliminate bias in the training data without eliminating a substantial percentage of your training data. Which would significantly hinder performance.
minus-squarebamboo@lemmy.blahaj.zonelinkfedilinkEnglisharrow-up10·9 months agoRather than eliminating the some of the training data, you could add more training data to create an even balance.
minus-squarekromem@lemmy.worldlinkfedilinkEnglisharrow-up3·9 months agoIndeed - there’s a very good argument for using synthetic data to introduce diversity as long as you can avoid model collapse.

{kind=link}
I mean, I don’t think it’s an easy thing to fix. How do you eliminate bias in the training data without eliminating a substantial percentage of your training data. Which would significantly hinder performance.
Rather than eliminating the some of the training data, you could add more training data to create an even balance.
Indeed - there’s a very good argument for using synthetic data to introduce diversity as long as you can avoid model collapse.