

Google is embedding inaudible watermarks right into its AI generated music::Audio created using Google DeepMind’s AI Lyria model will be watermarked with SynthID to let people identify its AI-generated origins after the fact.
Google is embedding inaudible watermarks right into its AI generated music::Audio created using Google DeepMind’s AI Lyria model will be watermarked with SynthID to let people identify its AI-generated origins after the fact.
This is the best summary I could come up with:
Audio created using Google DeepMind’s AI Lyria model, such as tracks made with YouTube’s new audio generation features, will be watermarked with SynthID to let people identify their AI-generated origins after the fact.
In a blog post, DeepMind said the watermark shouldn’t be detectable by the human ear and “doesn’t compromise the listening experience,” and added that it should still be detectable even if an audio track is compressed, sped up or down, or has extra noise added.
President Joe Biden’s executive order on artificial intelligence, for example, calls for a new set of government-led standards for watermarking AI-generated content.
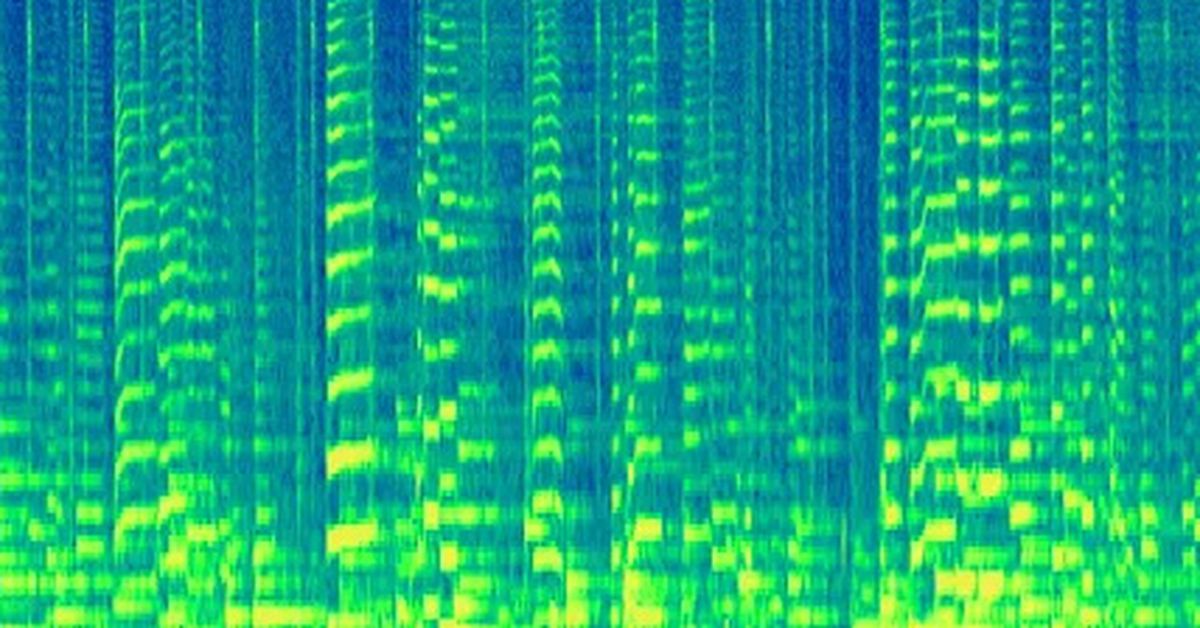
According to DeepMind, SynthID’s audio implementation works by “converting the audio wave into a two-dimensional visualization that shows how the spectrum of frequencies in a sound evolves over time.” It claims the approach is “unlike anything that exists today.”
The news that Google is embedding the watermarking feature into AI-generated audio comes just a few short months after the company released SynthID in beta for images created by Imagen on Google Cloud’s Vertex AI.
The watermark is resistant to editing like cropping or resizing, although DeepMind cautioned that it’s not foolproof against “extreme image manipulations.”
The original article contains 230 words, the summary contains 195 words. Saved 15%. I’m a bot and I’m open source!
Old school windows media player has entered the chat
Seriously fuck off with this jargon, it doesn’t explain anything
That’s actually an accurate description of what is happening: an audio file turned into a 2d image with the x axis being time, the y axis being frequency and color being amplitude.
That’s literally a spectrograph
Your mom’s literally a spectrograph.
Spectrogram*
I know, it’s like the old windows media player visualisations.
Sounds like a bad journalist hasn’t understood the explanation. A spectrogram contains all the same data as was originally encoded. I guess all it means is that the watermark is applied in the frequency domain.
Also this isn’t new by any stretch… Aphex Twin would like a word
Well, encoding stuff in the spectrogram isn’t new, sure. But encoding stuff into an audio file that is inaudible but robust to incidental modifications to the file is much harder. Aphex Twin’s stuff is audible!
I would like to know what it is that makes it so robust. The article explains very little. Is it in the high frequencies? Higher than the human ear can hear? Compression will effect that plus that’s going to piss dogs off. Could be something with the phasing too. Filters and effects might be able to get rid of the water mark
I don’t know what frequencies are annoying for dogs but I’m guessing it’s above 24kHz so no sound file or sound system is going to be able to store or produce it anyway.
There will certainly be some way to get rid of the watermark. But it might nevertheless persist through common filters.