- 478 Posts
- 48 Comments




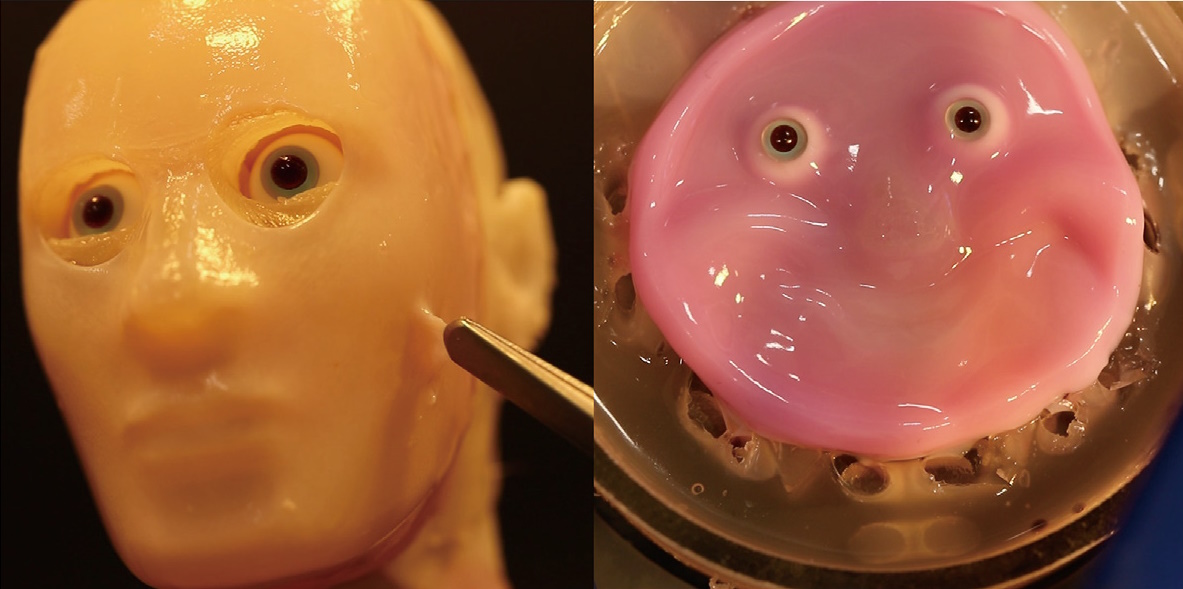


















 36·5 months ago
36·5 months agoJust for reference, a few years back, (ex-Microsoft) David Plummer had this historical dive into the (MIPS) origin of the blue color, and how Windows is not blue anymore: https://youtu.be/KgqJJECQQH0?t=780
Likely due to being a prototype. Production laptops from Tuxedo tend to have the “TUX” penguin in a circle logo on the Super key by default. They also have been offering custom engraved keyboard (even with the entire keyboard engraved from scratch to the customer’s specifications) as added service, so probably there will be suppliers or production facility to change the Super key.
By the way, there was one YouTube channel that ended up ordering a laptop with Windings engraving from them: https://youtu.be/nidnvlt6lzw?t=186
 1·6 months ago
1·6 months agoHow does this analogy work at all? LoRA is chosen by the modifier to be low ranked to accommodate some desktop/workstation memory constraint, not because the other weights are “very hard” to modify if you happens to have the necessary compute and I/O. The development in LoRA is also largely directed by storage reduction (hence not too many layers modified) and preservation of the generalizability (since training generalizable models is hard). The Kronecker product versions, in particular, has been first developed in the context of federated learning, and not for desktop/workstation fine-tuning (also LoRA is fully capable of modifying all weights, it is rather a technique to do it in a correlated fashion to reduce the size of the gradient update). And much development of LoRA happened in the context of otherwise fully open datasets (e.g. LAION), that are just not manageable in desktop/workstation settings.
This narrow perspective of “source” is taking away the actual usefulness of compute/training here. Datasets from e.g. LAION to Common Crawl have been available for some time, along with training code (sometimes independently reproduced) for the Imagen diffusion model or GPT. It is only when e.g. GPT-J came along that somebody invested into the compute (including how to scale it to their specific cluster) that the result became useful.
This is a very shallow analogy. Fine-tuning is rather the standard technical approach to reduce compute, even if you have access to the code and all training data. Hence there has always been a rich and established ecosystem for fine-tuning, regardless of “source.” Patching closed-source binaries is not the standard approach, since compilation is far less computational intensive than today’s large scale training.
Java byte codes are a far fetched example. JVM does assume a specific architecture that is particular to the CPU-dominant world when it was developed, and Java byte codes cannot be trivially executed (efficiently) on a GPU or FPGA, for instance.
And by the way, the issue of weight portability is far more relevant than the forced comparison to (simple) code can accomplish. Usually today’s large scale training code is very unique to a particular cluster (or TPU, WSE), as opposed to the resulting weight. Even if you got hold of somebody’s training code, you often have to reinvent the wheel to scale it to your own particular compute hardware, interconnect, I/O pipeline, etc… This is not commodity open source on your home PC or workstation.
The situation is somewhat different and nuanced. With weights there are tools for fine-tuning, LoRA/LoHa, PEFT, etc., which presents a different situation as with binaries for programs. You can see that despite e.g. LLaMA being “compiled”, others can significantly use it to make models that surpass the previous iteration (see e.g. recently WizardLM 2 in relation to LLaMA 2). Weights are also to a much larger degree architecturally independent than binaries (you can usually cross train/inference on GPU, Google TPU, Cerebras WSE, etc. with the same weights).
There is even a sentence in
README.mdthat makes it explicit:The source files in this repo are for historical reference and will be kept static, so please don’t send Pull Requests suggesting any modifications to the source files […]
There has been:
 291·7 months ago
291·7 months agoHe was criticized also because the girls were not in danger of becoming infected. See e.g. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6724388/ :
The Chinese episode has also generated other issues. Several notes demonstrate that this was an experiment and not a therapeutic intervention (even He Jiankui called it a ‘clinical trial’). The babies were not at risk of being born with HIV, given that sperm washing had been used so that only non-infected genetic material was used. Further, even though one of the parents (or both) was infected, it did not mean the children were more prone to becoming infected. The risk of becoming infected by the parents’ virus was very low (Cowgill et al., 2008). In sum, there was no curative purpose, nor even the intention to prevent a pressing risk. Finally, the interventions were different for each twin. In one case, the two copies of CCR5 were modified, whereas in the other only one copy was modified. This meant that one twin could still become infected, although the evolution of the disease would probably be slower. The purpose of the scientific team was apparently to monitor the evolution of both babies and the differences in how they reacted to their different genetic modifications. This note also raised the issue of parents’ informed consent regarding human experimentation, which follows a much stricter regimen than consent for therapeutic procedures.
Other critical articles (e.g. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8524470/) have also cited in particular https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4779710/, which states in the result section:
No HIV transmission occurred in 11,585 cycles of assisted reproduction using washed semen among 3,994 women (95% confidence interval [CI] = 0–0.0001). Among the subset of HIV-infected men without plasma viral suppression at the time of semen washing, no HIV seroconversions occurred among 1,023 women following 2,863 cycles of assisted reproduction using washed semen (95%CI= 0–0.0006). Studies that measured HIV transmission to infants reported no cases of vertical transmission (0/1,026, 95% CI= 0–0.0029). Overall, 56.3% (2,357/4,184, 95%CI=54.8%–57.8%) of couples achieved a clinical pregnancy using washed semen.
 61·8 months ago
61·8 months agoGIMP is a special case. GIMP is being getting outdeveloped by Krita these days. E.g.:
https://gitlab.gnome.org/GNOME/gimp/-/issues/9284
Or compare with:
https://www.phoronix.com/news/Krita-2024-GPUs-AI
GIMP had its share of self inflicted wounds starting with a toxic mailing list that drove away people from professional VFX and surrounding FilmGimp/CinePaint. When the GIMP people subsequently took over the GEGL development from Rhythm & Hues, it took literally 15 years until it barely worked.
Now we are past the era of simple GPU processing into diffusion models/“generative AI” and GIMP is barely keeping up with simple GPU processing (like resizing, see above).
Have people actually checked the versions there before making the suggestion?
F-Droid: Version 3.5.4 (13050408) suggested Added on Feb 23, 2023
Google Play: Updated on Aug 27, 2023https://f-droid.org/en/packages/org.videolan.vlc/
https://play.google.com/store/apps/details?id=org.videolan.vlcThe problem seems to be squarely with VLC themselves.

From my own statistics how many I feel worthy posting/linking on Lemmy, the most direct alternative to Kotaku is Eurogamer. PCGamer, PCGamesN and Rock Paper Shotgun are occasionally OK, but you have to cut through a lot of spam and clickbait (i.e. exactly this “50 guides per week” type of corporate guidance). Not sure if this is also the state that Kotaku will end up in. The Verge sometimes also have good articles, but the flood of gadget consumerism articles there is obnoxious.
 2·8 months ago
2·8 months agoIt is like the U.S. Wired catching up to the idea years later?
 1·8 months ago
1·8 months agoThe PS Vita side of Sony customer has gotten a deep taste of Sony’s issues of catering everything to a singular console. And same with PSVR2: Of course it must be PS5 exclusive, because everything are adornments towards their shiny console — and went on to not sell a lot of PS5.

In the beginning, only privileged ones will be allowed to run in pass-through mode. But goal/roadmap calls for all FUSE filesystems eventually to have this near-native performance.
Well, if you have a constructive suggestion which site to link instead regarding kernel developments, I am all ears:
- Not sure that raw commits are readable or have sufficient context for non kernel development readers here
- LWN, particularly timely/kernel development news there, has gone mostly paywall, and there will be (legitimate) complaint if I link articles needing a LWN subscription
Not sure what called for this blatant personal attack. My post history speaks for itself, quite in comparison to yours. And Phoronix is well-known Linux website, and its test suite is in fact even referenced in various regression tests/patches in LKML (also not sure what/if any kind of kernel development you have done).
There is pre-existing context and criticism. And it is not about, or just being the perception of “this journalist”:
https://www.theverge.com/23992402/geoff-keighley-the-game-awards-layoffs
https://videogames.si.com/features/games-industry-deserves-better-than-geoff-keighley
https://www.inverse.com/gaming/the-game-awards-2023-needs-to-acknowledge-industrys-lay-offs-problem
https://dotesports.com/the-game-awards/news/the-game-awards-layoffs-developers-no-respect
The problems also goes beyond just the layoffs, but his overt coziness and preferential treatment of large studios, over even the ones that actually won the award he is presiding over, and are supposed to be celebrated:
https://insider-gaming.com/geoff-keighley-shows-cowardice-at-the-game-awards/
https://www.eurogamer.net/the-game-awards-speeches-were-too-short-geoff-keighley-admits
Three side remarks about China, which can be a peculiar example to compare to for Russia, maybe even any other country: